
Wayve has developed a new ‘show and tell’ feature in LINGO-1, its vision-language-action model (VLAM) that helps explain the reasoning behind a self-driving car’s decisions and driving actions. The new feature uses referential segmentation to visually highlight the focus of LINGO-1’s attention and enhances the connection between language and vision tasks, ultimately allowing for more accurate and trustworthy responses.
As an open-loop driving commentator, LINGO-1 uses text to answer questions about a driving scene. With this latest development, Wayve says it has gone beyond the text description of objects in a scene, by adding a ‘show and tell’ capability that enables LINGO-1 to visually indicate its focus of attention. A blog on its website about this latest development states: “Referential segmentation paves the way for multimodal explainability through cross-verification. By dynamically highlighting objects of interest, LINGO-1 demonstrates a holistic understanding of the scene.”
For example, the video below demonstrates how LINGO-1 reasons about potential hazards while driving at night, first verifying that the scenario involves driving in the dark and then highlighting the potential hazards.
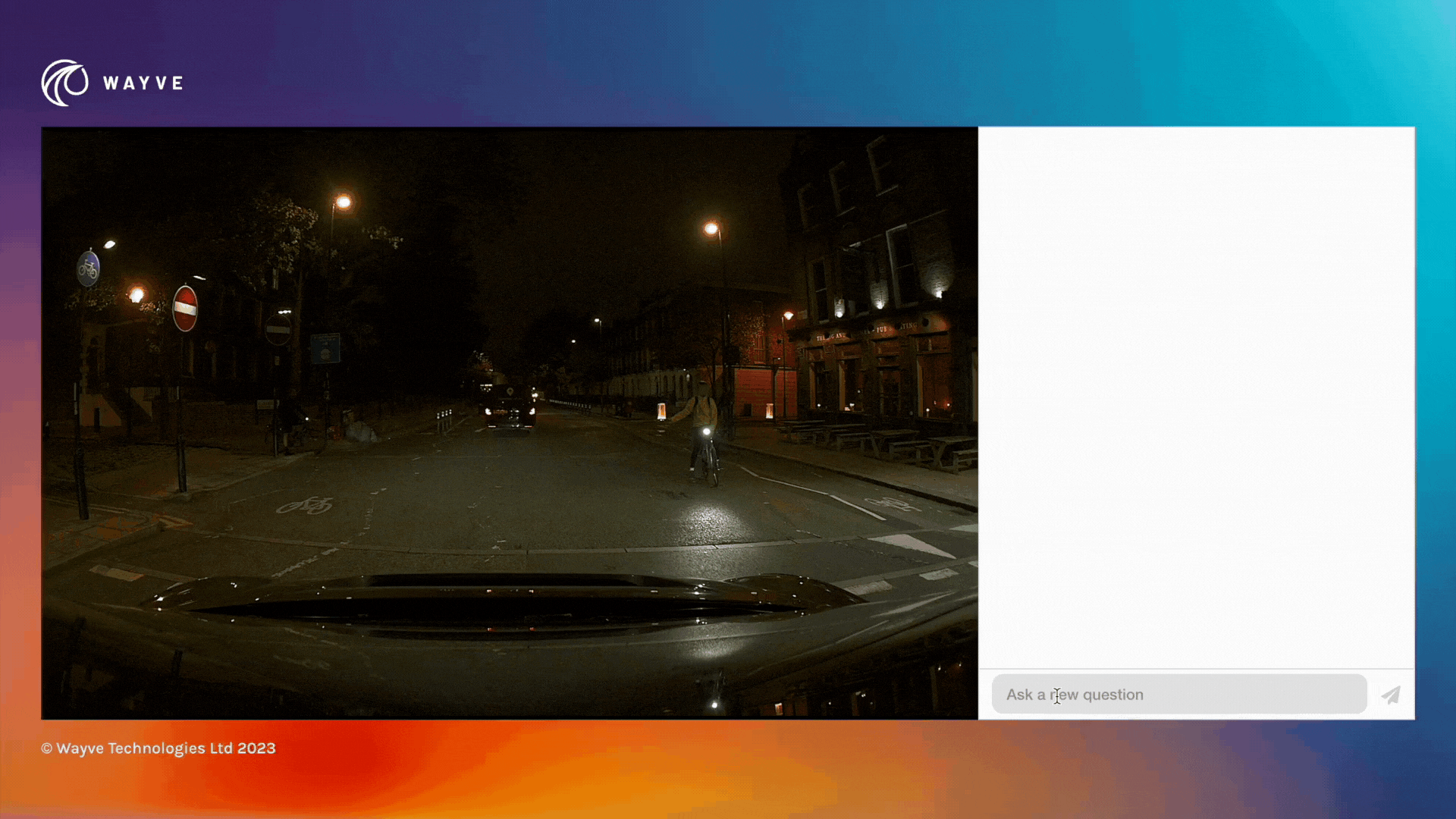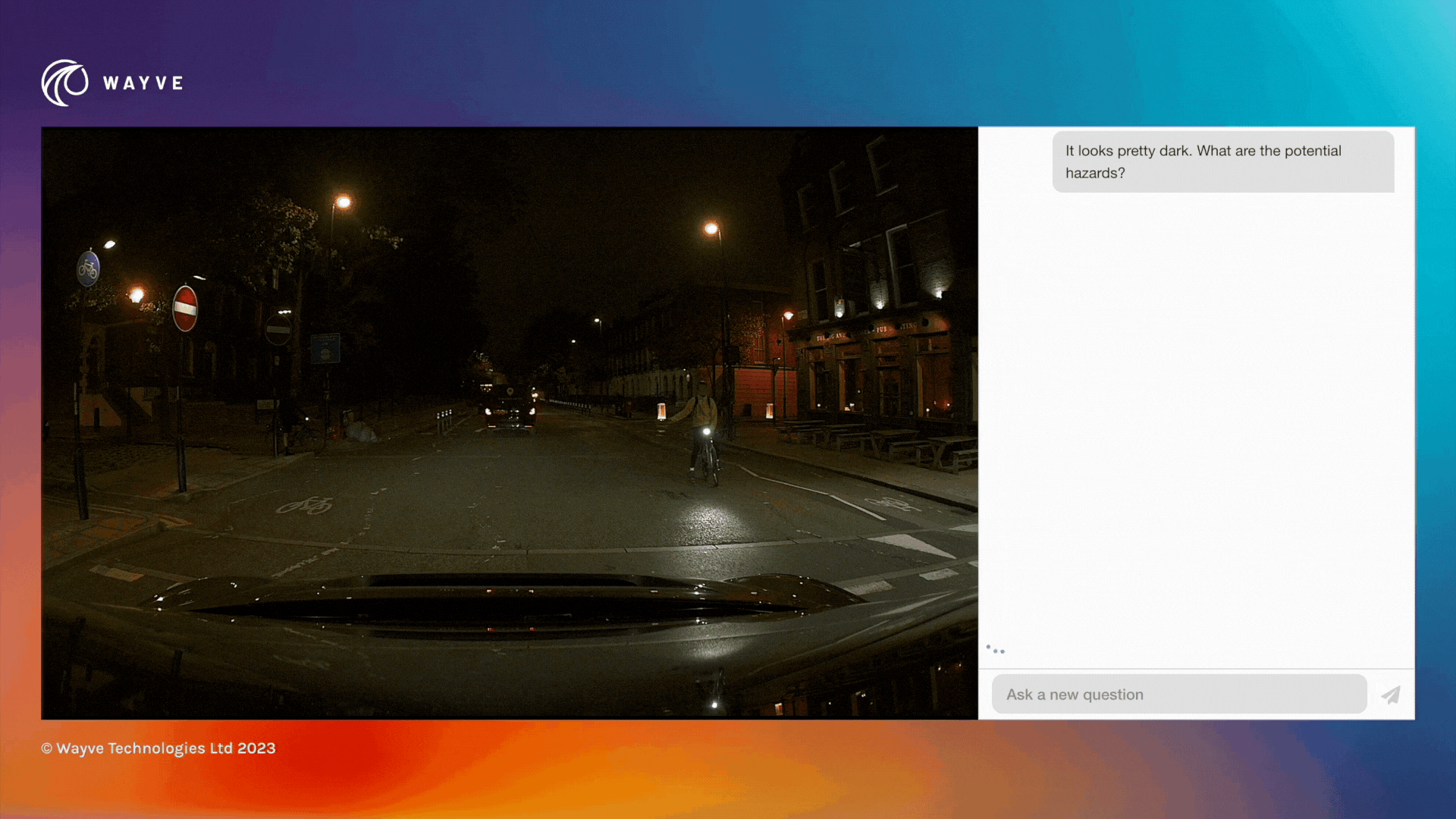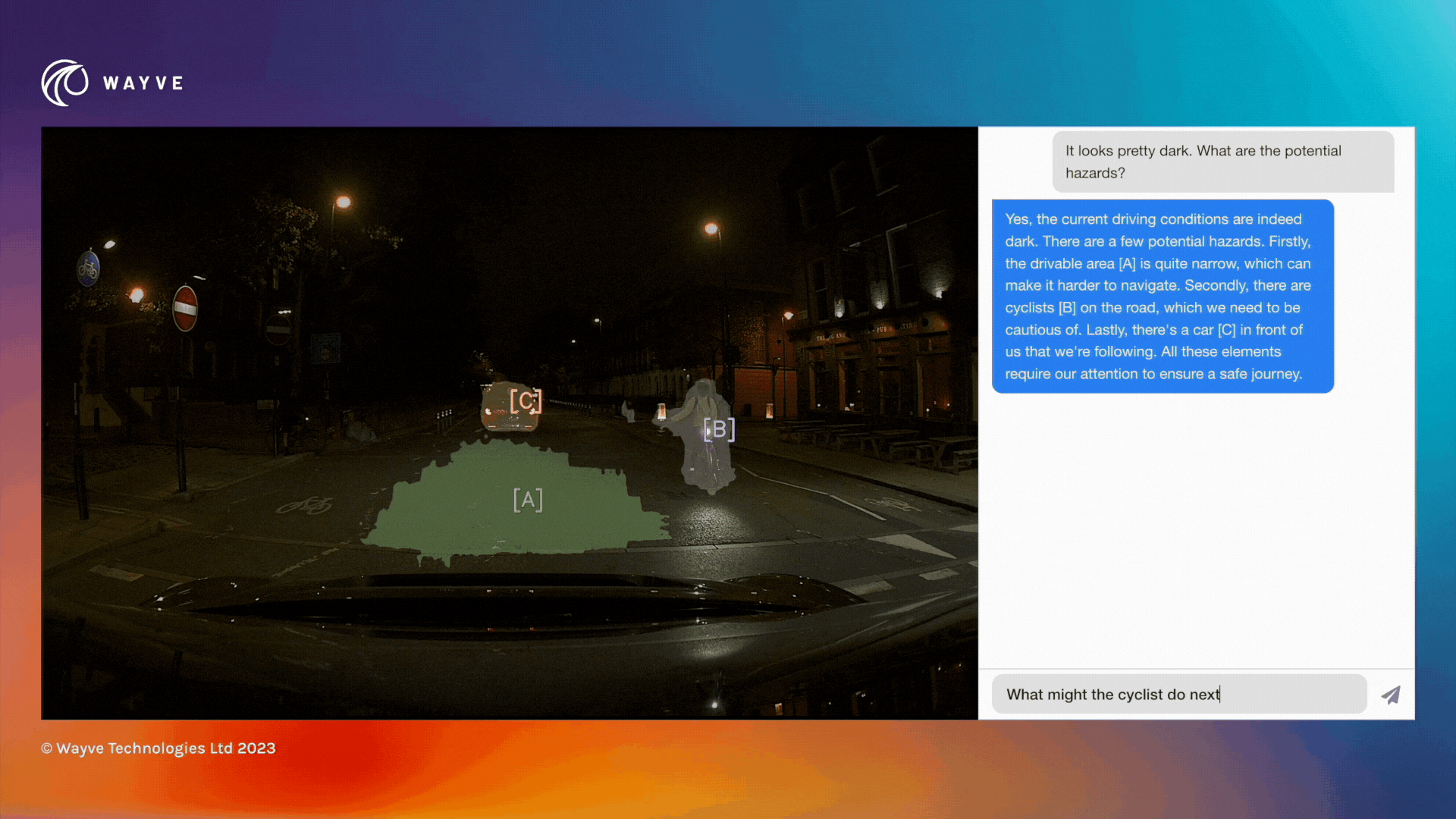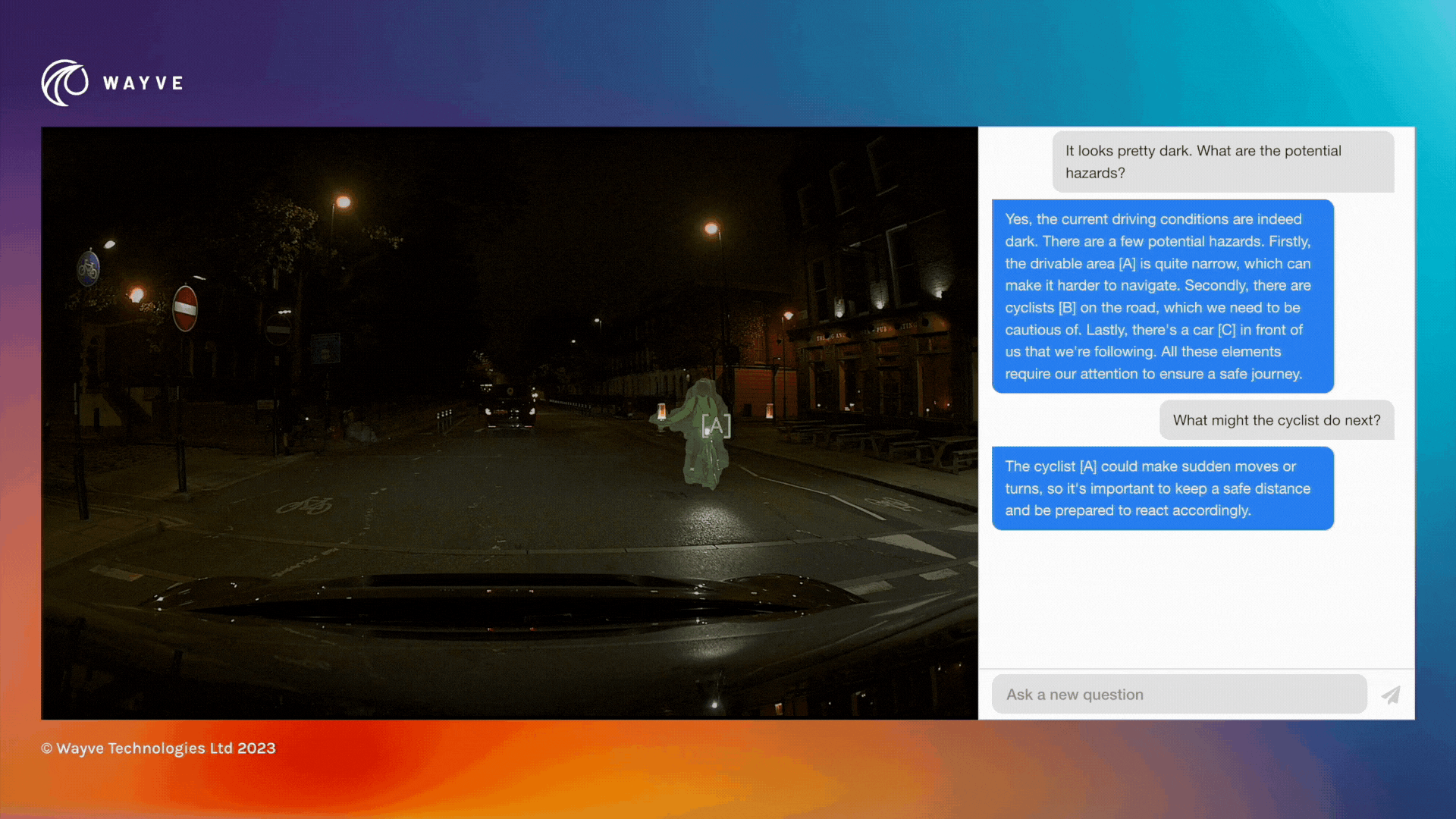
The company says this new development establishes a stronger ‘grounding’ (or connection) between language and vision tasks. It says the use of referential segmentation will increase the confidence in the accuracy and relevance of LINGO-1’s responses by mitigating the risk of hallucinations, speeding up the training process and improving safety communication (e.g. by highlighting potential hazards in a scene).
To develop its new capability, Wayve extended the architecture of LINGO-1 and trained it using data sets specific to the AV domain. These data sets imbue the model with multi-tasking capabilities – as a result, it can respond with text and perform referential segmentation simultaneously. The company adds it has also developed efficient protocols for gathering and curating such multimodal data sets for training and validation.
The following potential use cases are designed to show where referential segmentation could have the greatest impact:
Enhanced training and adaptability: By linking language and vision, Wayve says it can speed up the learning process by providing more efficient supervision to these models and more information about the scene. This learning ability is critical to address long-tail scenarios in driving where there are more limited examples.
Addressing hallucinations with LLMs: Hallucinations are a well-known problem in large language models; LINGO-1 is no exception. By developing the capability to ground language with vision, Wayve can introduce additional sources of supervision that would compel its model to respond only to objects that it can accurately identify in the scene, which can help mitigate the risk of hallucinations.
Improved safety communication: By visually highlighting potential hazards in the scene, LINGO-1 can effectively communicate critical information such as the position of pedestrians, cyclists or obstacles. This can play a vital role in building trust and confidence in the capabilities of AV technology.
The company says its new ‘show and tell’ feature represents a crucial step toward the development of Vision-Language-X Models (VLXMs), where ‘X’ encompasses diverse multimodal outputs such as language, referential segmentation, driving plans and raw control signals.
“By integrating these elements, Wayve is not only enhancing how AVs perceive and interpret their surroundings but also how they communicate this understanding – resembling a more human-like approach to driving,” the blog continues. “As a result, Wayve is setting the stage for a future where self-driving vehicles can clearly and effectively convey intentions and actions to passengers, pedestrians and other road users, ultimately contributing to the development of safer and more trustworthy autonomous driving systems.”