 are coming for self-driving cars")
In an exclusive feature first published in the January 2024 issue of ADAS & Autonomous Vehicle International, Ben Dickson explores how breaking down the language barrier between humans and computers could open the door to myriad new autonomous driving applications.
For decades, science fiction has tantalized us with the concept of vehicles that can engage in conversation and respond to natural language commands. The advent of in-car smart assistants brought us a step closer to this vision, allowing us to use everyday language for tasks such as finding directions, locating parking spaces, playing music or catching up on the news.
Now, emerging research is hinting at an even more exciting future. Large language models (LLMs), the artificial intelligence systems behind products such as ChatGPT and Bard, could soon revolutionize our interactions with autonomous vehicles. These advances suggest a future where we converse with self-driving cars in ways previously confined to the realm of imagination. And with the rapid pace of advances in artificial intelligence, we are only at the beginning of discovering the possibilities of LLMs in AVs.
At the core of LLMs lies the transformer – a deep learning architecture introduced in 2017 by researchers at Google. Renowned for its ability to process vast amounts of sequential data, the transformer’s primary function is ‘next token prediction’. In simple terms, it takes a sequence of words and predicts the subsequent word or phrase.
The initial success of transformers was largely within the realm of natural language processing. This was partly due to the wealth of text data available from online sources such as Wikipedia and news websites. Such data formed the foundation for LLMs such as ChatGPT, which became the fastest-growing application in history.
However, the potential of LLMs extends far beyond text. Danny Shapiro, VP of automotive
at Nvidia, says, “If you’re curating the data and training these things on specific data sets, you can get something that will have very good results. The important thing is it doesn’t have to just be language, characters, words.”
Since their inception, LLMs have been harnessed for a diverse range of applications, such as writing software code, predicting protein structures and synthesizing voice. They have also become an important part of models such as Stable Diffusion and DALL-E – AI systems that take text descriptions and generate corresponding images.
Now, the research community is investigating how LLMs can be applied in novel areas such as robotics and autonomous vehicles. Central to these explorations are vision language models (VLMs). These enable LLMs to merge text with visual data and perform tasks like image classification, text-to-image retrieval and visual question answering.
“Image pixels ultimately can be used to generate the characters, words and sentences that can be used to be part of a new user interface inside of a car,” Shapiro says. “For example, the driver might be looking to the left to see if it’s clear and the front-facing camera could see a child walking across the street on the right and describe that to the driver so they know not to blindly just hit the accelerator and create an incident.”
LLMs for self-driving cars
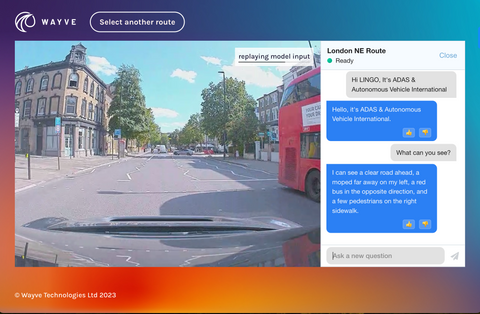
Self-driving car startup Wayve has been actively experimenting with the integration of LLMs into its AV systems. It recently unveiled Lingo-1, a groundbreaking model that facilitates conversation with the AI systems steering autonomous vehicles.
Jamie Shotton, chief scientist at Wayve, is optimistic about the potential of this technology. “The use of large language models will be revolutionary for autonomous driving technology,” he says. “Now, with Lingo-1, we are starting to see large language models enhance applications beyond the AI software and into the space of embodied AI such as our AI models for self-driving vehicles.”
Lingo-1 is designed to perform a wide array of tasks. It can answer questions about scene understanding, and reason about the primary causal factors in a scene that influence driving decisions. Essentially, it aims to provide a detailed narrative of the driving actions and the reasoning behind them.
“Currently Lingo-1 acts as an open-loop driving commentator, which offers driving commentary that explains the reasoning behind driving actions and allows us to ask questions about various driving scenes,” Shotton says. “These features allow us to understand in natural language what the model is paying attention to, and the ‘why’ behind the course of action it takes.”
In practical terms, Lingo-1 can explain the car’s decisions as it navigates through traffic. It can articulate why it’s maintaining or changing its speed, braking or overtaking another vehicle. Furthermore, it can respond to user queries about why it performed a certain action, the road conditions and visibility, or specific hazards in a given road situation.
Shotton believes that the integration of language into autonomous vehicle systems can lead to more efficient training and a deeper understanding of end-to-end AI driving systems. “Leveraging language through AI tools like Lingo-1 can increase the safety of these systems by aligning driving models to natural language sources of safety-relevant knowledge bases, such as the UK’s Highway Code, and updating alongside them,” he says. “In turn, language-based interfaces will help build confidence in ADAS and AV technology and the safer, smarter and more sustainable future of transportation they promise.”
Training LLMs for autonomous driving
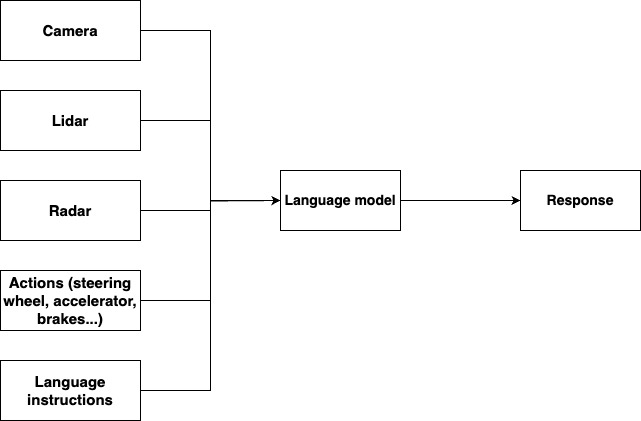
LLMs require vast amounts of high-quality training data, which poses a challenge in applications where data is not readily available. A common solution to this issue is to ‘fine-tune’ existing models. In this approach, a ‘foundation model’ that has been pre-trained on a comprehensive corpus of online data is further trained on a smaller data set of examples curated for a specific application, known as the ‘downstream task’.
Collecting data for these downstream tasks is still challenging. For instance, models like ChatGPT were trained on tens of thousands of instruction-following examples manually written by human experts, a costly and complex effort. When it comes to autonomous vehicles, the task becomes even more complex because it requires coordinating natural language instructions, visual data and actions.
To train Lingo-1, the Wayve team devised a unique approach. They created a data set that incorporates image, language and action data collected with the help of expert drivers who commented on their actions and the environment as they drove on UK roads.
The team adopted the commentary technique used by professional driving instructors during their lessons. These instructors help their students learn by example, using short phrases to explain interesting aspects of the scene and their driving actions. Examples include ‘slowing down for a lead vehicle’, ‘slowing down for a change in traffic lights’, ‘changing lanes to follow a route’ and ‘accelerating to the speed limit’.
The expert drivers were trained to follow a commentary protocol, focusing on the relevance and density of words and ensuring their commentary matched their driving actions. These phrases were then synchronized with sensory images recorded by cameras and low-level driving actions captured by car sensors. The result was a rich vision-language-action data set that was used to train the Lingo-1 model for a variety of tasks.
The Wayve researchers highlighted the efficiency of this approach in a September 2023 paper, stating, “Our driving commentary data enhances our standard expert driving data set collection without compromising the rate at which we collect expert driving data – enabling a cost-effective approach to gather another layer of supervision through natural language.”
Dealing with hallucinations
A known issue with LLMs is ‘hallucinations’, a phenomenon that happens when the model generates text that appears plausible but is factually false. For instance, a model might make incorrect statements about historical or scientific facts that could mislead someone lacking in-depth knowledge in that specific field.
While hallucinations may not pose significant problems in non-sensitive applications where users have ample time and resources to verify the information, they can be potentially fatal in time- and safety-critical applications such as driving and healthcare.
Researchers are striving to solve this problem. Part of the solution lies in setting boundaries on what the model can generate. Nvidia’s Shapiro says, “The models used inside vehicles will be fine-tuned on a curated version of the broad information used in general LLMs such as ChatGPT.”
To help tackle challenges such as hallucination, Nvidia has developed NeMo, a framework for customizing LLMs. With NeMo, developers can fine-tune language models with their own data and set guardrails to prevent them from straying into areas where they are not safe or reliable. NeMo is particularly efficient at working with pre-trained models.
“What we’re focused on is how do you leverage the core technology but do it in a way that prevents hallucinations,” Shapiro says. “The results are only as good as the data that goes in. So you need to curate the data that goes in and put guardrails on the topics that you want the system to be able to cover.”
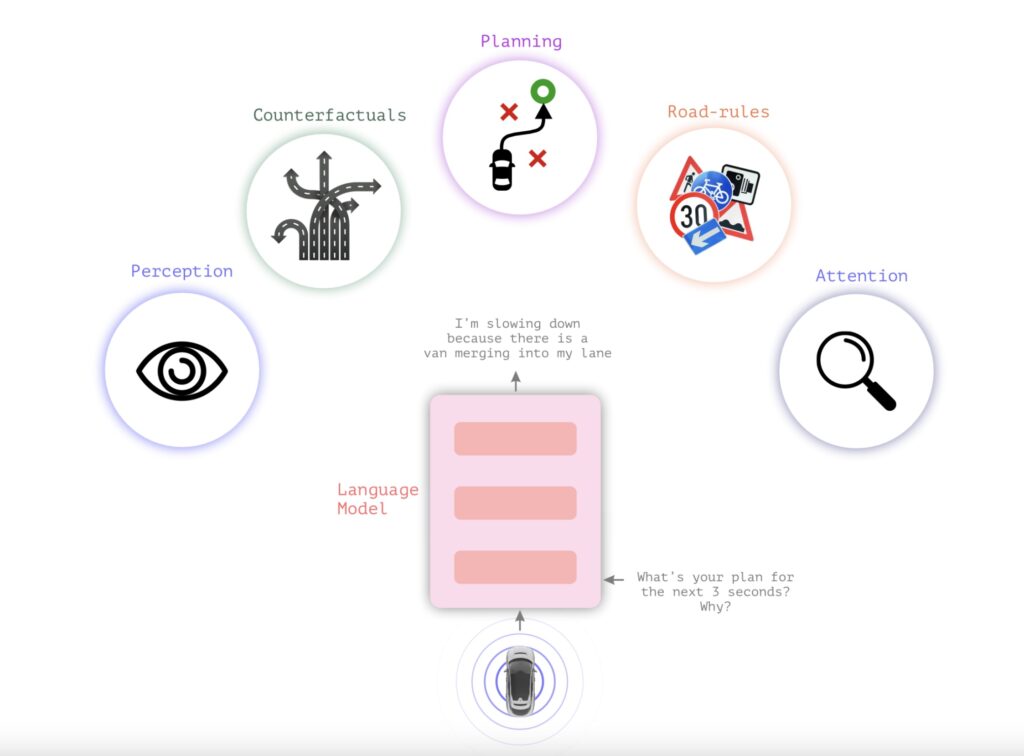
Wayve is addressing the issue of hallucinations through a technique known as reinforcement learning from human feedback (RLHF). This method ensures that LLMs align with the goals and intentions of users. The researchers also believe that the multimodal nature of Lingo-1 will make it more robust against hallucinations than text-only LLMs.
“Since Lingo-1 is grounded in vision, language and action, there are more sources of supervision that allow it to understand the world better,” the researchers wrote. “It can learn to reason and align its understanding between text descriptions, what it sees in the video and how it interacts with the world, increasing the sources of information that can allow it to understand causal relationships.”
The computation bottleneck
Large language models require substantial computational power for training and operation. The most advanced models, such as GPT-4, can only function on cloud servers. For time-critical applications like autonomous vehicles, these models must be adapted to run on the onboard computers. Achieving this requires solutions that can shrink the models and make them faster without sacrificing their performance.
There’s already a wealth of research aimed at making these models more efficient by modifying their architecture or training data. For instance, some studies have shown that smaller LLMs continue to improve as their training data set expands. Other research employs quantization, a technique that reduces the size of individual parameters in an LLM while minimizing the impact on its performance. These techniques will be instrumental in harnessing the power of LLMs for self-driving cars.
In addition to these efforts, there are hybrid solutions that can enable autonomous vehicles to use LLMs both on board and in the cloud. “We try to do as much as we can in the car, especially for tasks that we have immediate data for on board. It will be much faster and have very low latency when we don’t have to go to the cloud,” Shapiro says. “But there will be cases where we would go to the cloud for additional information or insight or content that isn’t available on the vehicle.”
Solving the problems of the future
Breaking down the language barrier between humans and computers opens the door to myriad new applications. We’re already witnessing how LLMs such as ChatGPT are transforming tasks that traditionally require rigid user interfaces and instructions.
Yet we’re only beginning to discover the full potential of LLMs. As newer models and technologies emerge, engineers will undoubtedly continue to explore ways to harness their power in various fields, including autonomous vehicles.
“By adding natural language to our AI’s skill set we are accelerating the development of this technology while building trust in AI decision making, and this is vital for widespread adoption,” Wayve’s Shotton says.
Currently, models such as Lingo-1 are demonstrating the promise of enhanced explainability and communication. As researchers refine the process of curating the right training data and setting the appropriate guardrails, these models may evolve and start tackling more complex tasks.
“In reality, LLMs in AVs are going to start off small and continue to grow,” Nvidia’s Shapiro says. “That’s the promised beauty of a software-defined car. Like your phone, it gets software updates; your car will get smarter and smarter over time. It mimics us as humans: when you’re a kid, you have limited knowledge and every day you learn something new. As you grow, your vocabulary and your understanding increase. And that’s really what we’re doing with these vehicles.”
This feature was first published in the January 2024 issue of ADAS & Autonomous Vehicle International magazine – you can find our full magazine archive, here. All magazines are free to read. Read the article in its original format here.
